Beyond the Code: An Engineering Leader's Introduction to Building Analytics That Deliver Real Value

Introduction: Navigating the Data Deluge
As engineering leaders and software engineers, we live and breathe data. Logs, metrics, performance traces, user events, financial transactions – it's a constant stream. But are we truly using this data to make better decisions? Or are we just drowning in it?
In today's fast-paced world, the ability to extract meaningful insights from the ocean of data is no longer a luxury; it's a fundamental requirement for building successful products, optimizing operations, and driving business growth. This is where analytics comes in.
An effective analytics platform transforms raw data into actionable intelligence. It helps us understand user behavior, measure the impact of features, identify bottlenecks in our systems, predict future trends, and ultimately, make informed, data-driven decisions that move the needle.
If you're already steeped in the world of data pipelines, data warehouses, and sophisticated BI tools, parts of this introduction might feel basic. Feel free to skim or skip ahead. This post is specifically designed as a primer for those new to formal analytics initiatives, focusing more on the foundational concepts and strategic thinking rather than diving deep into technical implementations.
Over the next few thousand words, we'll break down the core components of getting into analytics:
- Understanding your Data: Where it lives, what types exist, and the inherent challenges in working with it.
- Processing the Data: A high-level look at ETL/ELT and the role of automation.
- Extracting Insights: How Business Intelligence (BI) tools help visualize and analyze data.
My goal is to provide a clear, practical roadmap for approaching analytics within your engineering organization. We'll particularly emphasize the importance of starting with the outcome you want to achieve. Automating the wrong thing, no matter how elegantly coded, is a waste of valuable engineering resources.
This post is just the beginning. In our next article, we'll build upon these concepts and walk through setting up a basic analytics platform suitable for gaining initial business intelligence.
Let's dive in.
The Three Pillars: Deconstructing the Analytics Pipeline
At its core, any analytics initiative, whether a simple spreadsheet analysis or a multi-million dollar data platform, involves three fundamental stages. Think of it as a pipeline:
- Data Sources & Types: This is where your raw material comes from – the applications, databases, logs, third-party services, and even manual entries that generate data relevant to your business and operations. Understanding what data you have and where it resides is the absolute first step.
- Data Processing (ETL/ELT): Once you know where the data is, you need to move it, clean it, transform it, and prepare it for analysis. This often involves Extracting data from sources, Transforming it into a usable format, and Loading it into a destination optimized for querying. This is typically where engineering and scripting skills come into play, often using languages like Python or R, or specialized data integration tools.
- Business Intelligence (BI) & Insights: The final stage is consuming the prepared data to generate reports, build dashboards, perform ad-hoc analysis, and ultimately, gain insights that inform decisions. This is where BI tools shine, making data accessible and understandable to a wider audience, including non-technical stakeholders.
Here's a critical point, especially for engineering teams who love to build elegant systems: While the automation in step 2 is essential for scalability and efficiency in the long run, steps 1 and 3 are the most crucial to get right initially.
Why? Because you need to know:
- What data do I have access to (Step 1)? If the data doesn't exist or is inaccessible, no amount of processing magic will help.
- What questions am I trying to answer, and what insights do I need to drive decisions (Step 3)? This is the goal.
Think of it this way: If you don't know what house you want to build (Step 3 - the insights/goal) and what materials you have available (Step 1 - the data sources), spending time designing an automated system to transport bricks (Step 2 - ETL/ELT automation) is premature and likely wasteful.
You can start by manually gathering data into a spreadsheet (a rudimentary Step 2) and manually creating charts (a rudimentary Step 3) to validate the data sources (Step 1 is confirmed) and ensure the manual insights are valuable. Only once you've proven the value of the data and the insights should you invest heavily in automating the processing pipeline.
No amount of sophisticated ETL/ELT scripting skill can generate value from irrelevant or incorrect source data, or produce insights that nobody needs. You'll just be highly automating the process of producing useless output.
These three components don't operate in isolation. They form a cycle. The insights gained from BI often reveal the need for new data sources or require refinements in the data processing stage. A well-designed analytics platform ensures a smooth flow through this pipeline, enabling individuals across the organization, from engineers and product managers to sales and executives, to access and understand the data they need to make informed decisions, track performance, identify opportunities, and troubleshoot issues.
Data Sources and Types: The Raw Materials of Insight
Data is everywhere. Our applications generate logs, users click buttons, servers report their health, payments are processed, marketing campaigns gather leads – every interaction and operation within a business creates data. The first major hurdle in analytics is identifying where your relevant data resides and understanding its nature.
The location and type of data depend heavily on your industry, domain, and the specific problem you're trying to solve. However, certain patterns are common across many businesses.
Here's a table illustrating some typical data types and their common homes:
| Data Type | Description | Common Sources / Locations | Examples of Vendors/Tools |
|---|---|---|---|
| Financial Data | Revenue, expenses, transactions, budgets, invoices, payroll. | Accounting systems, payment gateways, ERP systems, spreadsheets, data warehouses. | Xero, QuickBooks, SAP, Oracle Financials, Stripe, PayPal |
| Operational Tech Data | Server metrics (CPU, memory, disk), application performance monitoring (APM), logs, infrastructure costs, error rates, uptime. | Monitoring systems, logging platforms, cloud provider metrics, ticketing systems. | Prometheus, Grafana, Elastic Stack (ELK), Datadog, New Relic, AWS CloudWatch, Azure Monitor, Google Cloud Monitoring |
| User Behavior Data | Website clicks, app interactions, page views, session duration, conversion funnels, feature usage. | Web analytics platforms, product analytics tools, application databases, event streams. | Google Analytics, Mixpanel, Amplitude, PostHog, Heap |
| Product Data | User profiles, product catalogs, orders, feature flags, A/B test results, content details. | Application databases (SQL/NoSQL), internal tools, spreadsheets, feature flagging systems. | PostgreSQL, MySQL, MongoDB, Cassandra, DynamoDB, LaunchDarkly, Optimizely |
| Sales & CRM Data | Leads, contacts, opportunities, customer interactions, sales pipeline status. | CRM systems, sales automation platforms. | Salesforce, HubSpot, Zoho CRM, Pipedrive |
| Marketing Data | Campaign performance, ad spend, website traffic sources, lead generation. | Marketing automation platforms, advertising platforms, social media analytics. | Marketo, HubSpot Marketing, Google Ads, Facebook Ads Manager |
| Customer Support Data | Support tickets, customer interactions, resolution times, customer feedback. | Helpdesk software, CRM systems. | Zendesk, Intercom, ServiceNow |
This table is by no means exhaustive, but it highlights that relevant data for analysis is often scattered across numerous, disparate systems.
The Challenges of Working with Data
Once you've identified your potential data sources, you quickly encounter the inherent complexities of working with real-world data. Data isn't always neat, tidy, or immediately useful in its raw form.
Let's consider some common data types and their implications for analytics:
Granular (Event-Level) Data: This is the most detailed form, representing individual actions or events as they happen (e.g., a single user clicking a button, a single server log entry, a single transaction record).
- Pros: Provides the richest detail, allows for deep-dive analysis, enables flexible aggregation and slicing in many different ways, essential for understanding processes and user flows.
- Cons: High volume (can be massive), requires significant storage and processing power, can be complex to query and analyze directly.
- Usefulness: Understanding user journeys, debugging issues, detailed operational monitoring, fraud detection.
Aggregated Data: This data has been summarized over a period or group (e.g., total website visits per day, average CPU usage per server per hour, total revenue per month).
- Pros: Much smaller volume, easier to work with and visualize, good for high-level trends and reporting.
- Cons: Loses the detail of the individual events, makes it impossible to "drill down" to understand the underlying reasons for a trend without access to the granular data, less flexible for exploring new questions not considered during aggregation.
- Usefulness: High-level performance monitoring, executive summaries, tracking key metrics over time.
PII (Personally Identifiable Information) Data: Any data that can be used to identify a specific individual (e.g., name, email address, IP address, location data when tied to an identity).
- Pros: Necessary for personalized analysis, customer relationship management, targeted marketing.
- Cons: Requires strict handling due to privacy regulations (GDPR, CCPA), significant security risks if mishandled, often needs anonymization or pseudonymization for broad analytical use.
- Usefulness: Customer segmentation, personalization, understanding individual customer behavior (with caution and proper consent/anonymization).
Event-Type Data: A specific form of granular data that records when something happened, who did it, and what happened (e.g., "User X clicked button Y at time Z on page A"). This is foundational for understanding user behavior, process flows, and system interactions.
- Pros: Captures the sequence and context of actions, highly flexible for analyzing funnels, cohorts, and behavioral patterns.
- Cons: Can be extremely high volume, requires careful schema design to be useful.
- Usefulness: Product analytics, user journey analysis, system auditing, security monitoring.
Categorical Data: Data that falls into categories (e.g., product type, user role, error severity).
- Pros: Useful for grouping and filtering analysis.
- Cons: Can be messy if categories aren't standardized (e.g., "USA", "U.S.A.", "United States").
- Usefulness: Segmentation, comparison between groups.
Numerical Data: Quantitative data (e.g., price, duration, count, temperature).
- Pros: Enables mathematical calculations and statistical analysis.
- Cons: Requires understanding units and potential outliers.
- Usefulness: Calculating averages, sums, variances, trends, forecasting.
Beyond the types, the sheer act of bringing data together from different sources presents significant challenges:
- Data Silos: Data being isolated in different systems with no easy way to connect them.
- De-duplication: Identifying and merging records that represent the same entity (e.g., the same customer) but exist in multiple systems in slightly different formats.
- Trustworthiness & Correctness: Is the data accurate? Is it complete? Are there gaps, errors, or inconsistencies at the source? Data quality is paramount; analysis on bad data leads to bad decisions ("Garbage In, Garbage Out" - GIGO).
- Format Inconsistencies: Data stored in different formats (JSON, CSV, different database schemas, different date formats) that need standardization.
- Timeliness: How fresh does the data need to be for analysis? Real-time, daily, weekly? This impacts the complexity of the processing pipeline.
- Schema Evolution: Data sources (like application databases) change over time as features are added or modified, breaking assumptions made in the processing pipeline.
This is why, when starting out, mastering your data manually can be incredibly insightful. Pulling data into a spreadsheet or a local database and manipulating it there allows you to:
- Verify the data's availability and quality from the source.
- Experiment with different ways of joining or transforming the data.
- Build the exact tables or aggregations needed to answer your specific questions.
- Validate the formulas and logic required for your desired metrics and insights.
This manual "proof of concept" ensures you understand the data, its limitations, and precisely what the desired output looks like before you write complex automation code. Working backward from the desired insight (the chart you want to see, the question you need answered) dictates what data you need and how it needs to be shaped.
A key lesson learned by many organizations is that having fine-grained, granular data is almost always preferable to starting only with aggregated data. While aggregated data is smaller and seemingly simpler, you lose the ability to ask follow-up questions or view the data from different perspectives that weren't considered during the initial aggregation. With granular data, you can always aggregate it in multiple ways later. The tools and technologies available today are increasingly capable of handling "big data" volumes of granular information.
Typical Data Lakes and Data Warehouse Solutions
Given the challenges of disparate data sources and the desire for a centralized, reliable place for analysis, organizations often implement data lakes or data warehouses.
Data Warehouse: Traditionally, a data warehouse is a highly structured repository optimized for reporting and analysis. Data is typically cleaned, transformed, and structured before being loaded into the warehouse (ETL approach). It often uses a star or snowflake schema design to facilitate querying for BI purposes. Data warehouses are excellent for structured data and answering well-defined business questions.
Data Lake: A data lake is a vast pool of raw data stored in its native format (structured, semi-structured, or unstructured). The schema and transformation are applied when the data is read (schema-on-read, often associated with ELT). Data lakes are more flexible, allowing data scientists and analysts to explore data without predefined structures. They are cost-effective for storing large volumes of diverse data.
Many modern data platforms utilize aspects of both, sometimes referred to as a "Data Lakehouse," combining the flexibility of a data lake with the structure and management features typically associated with data warehouses.
These centralized repositories are crucial because they provide a "single source of truth." Instead of analysts pulling data inconsistently from various operational systems (potentially slowing them down or getting different results), they can query the data lake or warehouse, which is specifically designed and optimized for analytical workloads. This separation also protects your operational systems from heavy analytical queries.
Automation with ETL or ELT: Building the Data Pipeline
Once you know your data sources (Step 1) and the desired insights/output (Step 3), you can design and build the process to move and transform the data – Step 2, often involving ETL or ELT. This is where engineering skills become central to building a scalable analytics platform.
ETL (Extract, Transform, Load): Data is extracted from the source, transformed into the desired structure and format using a staging area, and then loaded into the target data warehouse or database. Transformation happens before loading. This is common when the target system (like an older data warehouse) isn't powerful enough to handle transformations efficiently or when significant cleaning is required upfront.
ELT (Extract, Load, Transform): Data is extracted from the source and loaded directly into the target system (often a powerful cloud data warehouse or data lake). The transformation then happens within the target system using its processing power (e.g., SQL queries within the data warehouse). This approach is increasingly popular with modern cloud platforms, as it allows data to be available faster and transformations can be more easily iterated upon or performed by analysts directly using SQL.
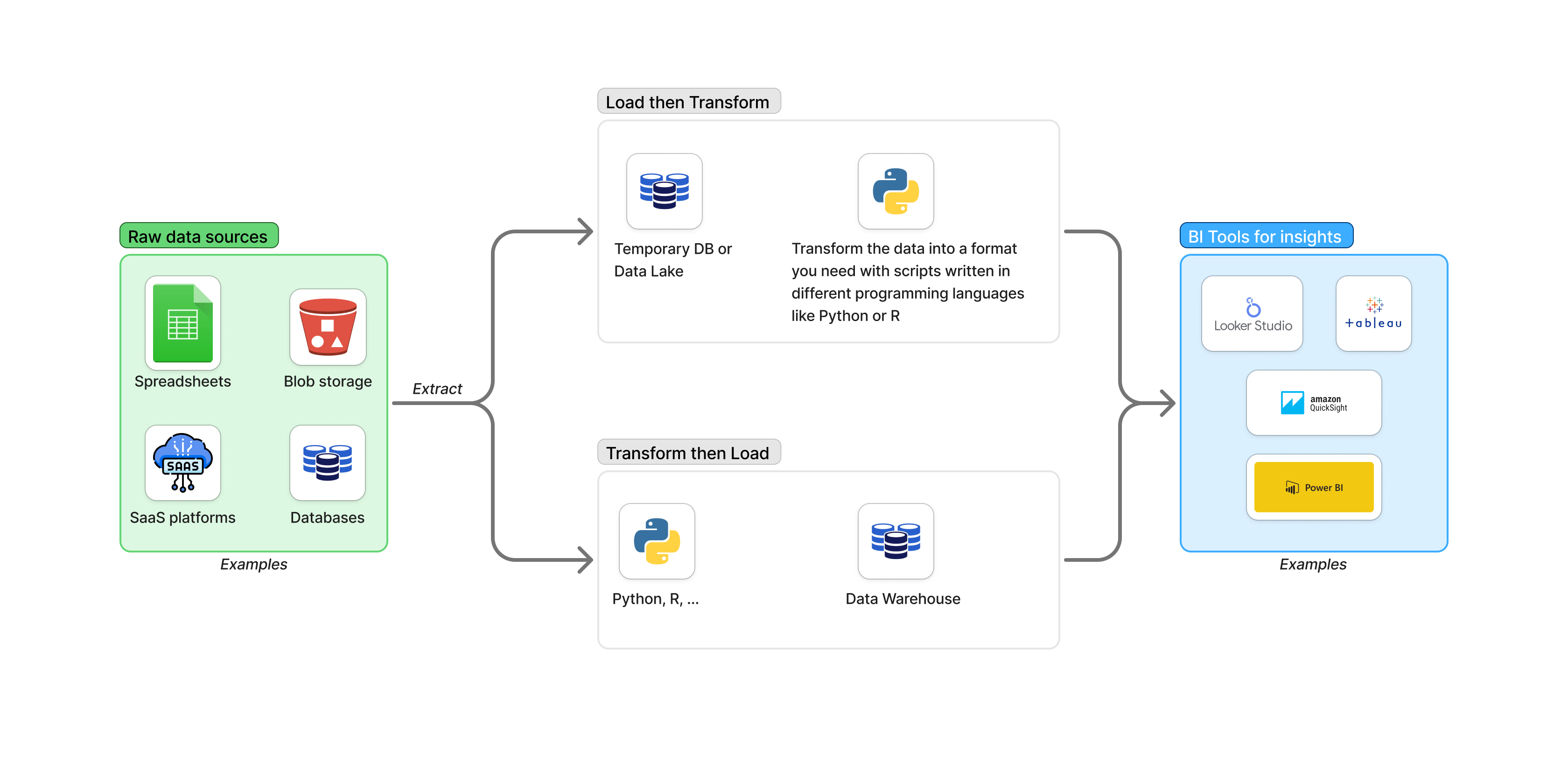
Typical workflows for engineers building these pipelines using programming tools like Python involve writing scripts or using frameworks to:
- Connect: Establish connections to various data sources (databases, APIs, cloud storage, file systems).
- Extract: Query databases, call APIs, read files, or subscribe to event streams to get the raw data.
- Clean & Transform:
- Handle missing values (impute, remove).
- Standardize formats (dates, text casing, units).
- Filter out irrelevant data.
- Join data from different sources based on common keys.
- Aggregate data to the desired level (if required for a specific use case, though often granular data is preferred).
- Create new calculated fields.
- Anonymize or pseudonymize sensitive data (PII).
- Load: Write the processed data into the target destination (e.g., tables in a data warehouse, files in a data lake, another database).
Python is a popular choice for these tasks due to its versatility and rich ecosystem of libraries. Some commonly used libraries include:
pandas: An incredibly powerful library for data manipulation and analysis. It provides DataFrames, which are like super-powered spreadsheets or SQL tables in memory, making cleaning, transforming, and analyzing tabular data highly efficient.- Database Connectors: Libraries like
psycopg2(PostgreSQL),mysql-connector-python(MySQL),pyodbc(for various databases including SQL Server),sqlalchemy(an ORM that provides a consistent interface to many database types). - API Libraries:
requestsis the de facto standard for making HTTP requests to pull data from web APIs. - Cloud SDKs: Libraries provided by cloud providers like
boto3(AWS),google-cloud-storage(GCP),azure-storage-blob(Azure) for interacting with cloud storage, databases, and other services. - Data Formatting: Libraries for working with specific formats like
json,csv,openpyxl(Excel),parquet,avro.
While building robust, automated data pipelines is a significant engineering effort, it's crucial to reiterate that this automation is not the starting point and can even be delegated or built iteratively. The priority is validating that the data sources contain the necessary information and that the transformed data leads to valuable insights. If you can achieve the initial insights using manual data pulls and spreadsheet manipulation, you've proven the concept and can then invest in automating that specific, validated process. Knowing the end goal allows others (including less senior engineers or even data analysts with scripting skills) to build the automation layer effectively.
Many enterprises deploy sophisticated data ingestion strategies to populate their data lakes and warehouses:
- Batch Processing: Running scripts or jobs periodically (e.g., daily, hourly) to extract data from sources that don't change rapidly or only need periodic updates. This is common for operational databases or file dumps.
- Micro-Batching: Processing data in small batches frequently (e.g., every few minutes) to provide fresher data than traditional batch processing.
- Event-Driven Architecture: Using message queues (like Kafka, Kinesis, Pub/Sub) to capture data events in near real-time as they occur. Producers write events to a topic, and consumers (your ingestion pipelines) read these events and load them into the data lake/warehouse. This is ideal for user behavior, IoT data, or transaction streams where low latency is required.
- Webhooks: Sources send automated HTTP POST requests to a specified endpoint whenever a specific event occurs, triggering your ingestion process.
- Change Data Capture (CDC): Techniques that identify and capture changes made to a database's tables in real-time, allowing those changes to be replicated to the data warehouse or lake.
- File Dumps into Blob Storage: Sources automatically export data files (CSV, JSON, Parquet) into cloud storage buckets (S3, GCS, Azure Blob Storage), which triggers ingestion processes.
- API Calls: Regularly polling APIs of third-party services (e.g., CRM, advertising platforms) to extract new or updated data.
These automated pipelines are the backbone of making data available for analysis at scale and with sufficient freshness. They also enable more advanced use cases like real-time analytics for monitoring, fraud detection, or personalized user experiences, where the processed data needs to be accessible with minimal latency.
What Can BI Tools Do to Help? Visualizing Data and Generating Insights
The final, crucial stage in the analytics pipeline is making the processed data accessible, understandable, and explorable for decision-makers. This is the realm of Business Intelligence (BI) tools.
BI tools are software applications designed to retrieve, analyze, transform, and report data for business intelligence. They connect to your prepared data source (ideally, your data warehouse or data lake) and provide user-friendly interfaces to visualize and interact with the data without needing to write code or complex database queries for every question.
Common examples of popular BI tools include:
- Microsoft Power BI: A widely used, relatively accessible tool, especially popular in organizations already using Microsoft products. Strong data modeling and visualization capabilities.
- Looker Studio (formerly Google Data Studio): A free, web-based tool that integrates well with Google's ecosystem (Google Analytics, Google Ads, BigQuery) but can connect to many other data sources. Easy to create shareable dashboards.
- Tableau: A powerful and highly regarded tool known for its intuitive drag-and-drop interface and strong data visualization capabilities. Often preferred by dedicated data analysts.
- Amazon QuickSight: AWS's BI service, integrating naturally with AWS data sources (S3, Redshift, RDS, Athena). Offers serverless options and embedded analytics.
- Other notable tools: Mode Analytics, Sisense, ThoughtSpot, Qlik Sense, Apache Superset (open source).
The utility of BI tools lies in their ability to:
- Connect to Diverse Data Sources: While ideally connecting to a centralized data warehouse/lake, many can connect directly to databases, cloud files, APIs, and SaaS applications (though this can lead to complexity if not managed).
- Enable Data Exploration: Allow users to slice, dice, filter, and drill down into data to understand underlying trends and outliers.
- Create Visualizations: Transform raw data into easily understandable charts, graphs, maps, and tables. This is critical for identifying patterns and communicating findings effectively.
- Build Interactive Dashboards and Reports: Combine multiple visualizations onto a single screen (a dashboard) or create paginated reports that can be shared across the organization. Interactive dashboards allow users to filter and explore the data themselves.
- Support Self-Service Analytics: Empower less technical users (product managers, marketing, sales, executives) to answer many of their own data questions without relying solely on the engineering or data team for every query.
- Facilitate Data Storytelling: Help users combine data, visuals, and narrative to communicate insights and influence decisions.
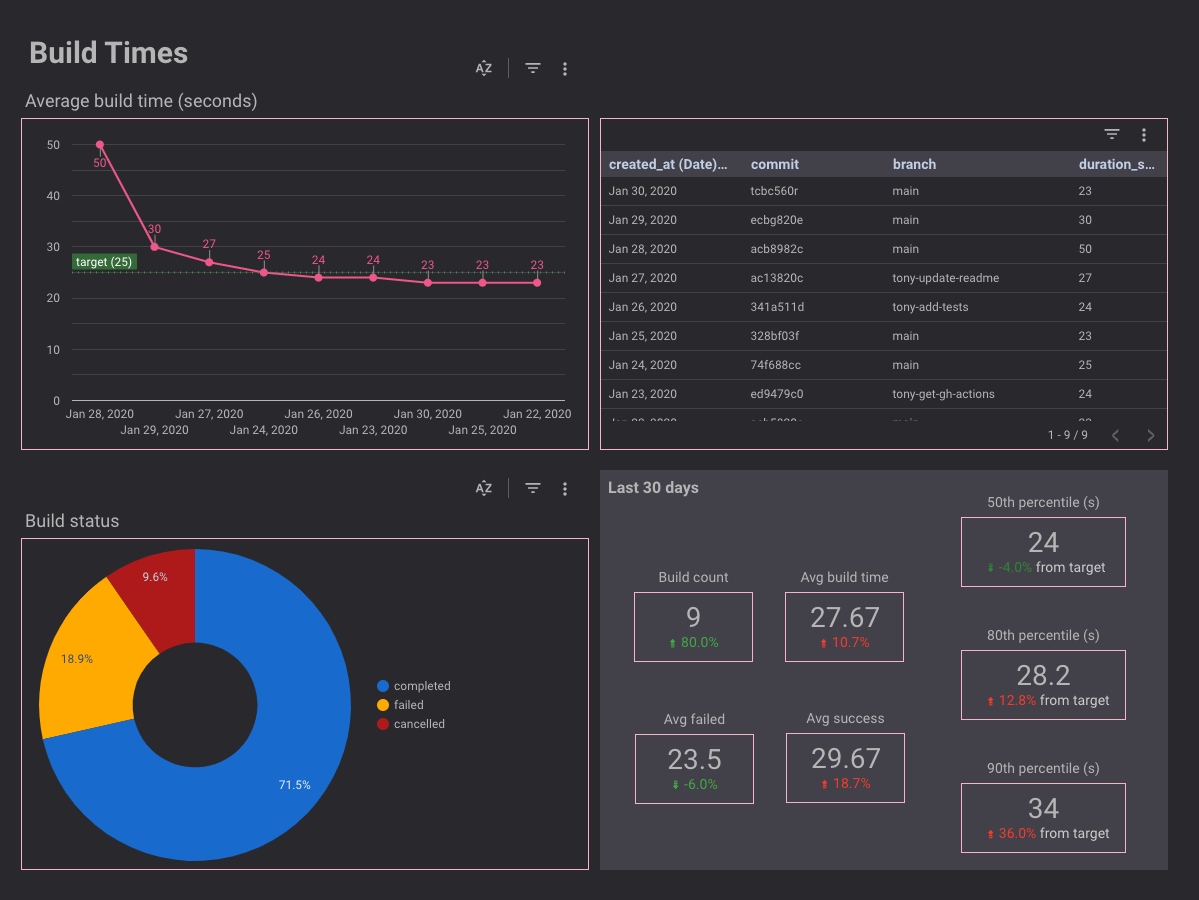 Example productivity dashboard for Engineering (build times). See this other article on productivity metrics with code on how this is done.
Example productivity dashboard for Engineering (build times). See this other article on productivity metrics with code on how this is done.
Typical workflows using BI tools often involve:
- A data professional (data engineer, analytics engineer, or analyst) prepares the data in the data warehouse/lake, ensuring it is clean, structured, and performant for querying.
- Analysts or business users connect the BI tool to this prepared data source.
- They drag and drop dimensions (categories like 'date', 'product name') and measures (numerical values like 'revenue', 'user count') onto a canvas to create visualizations.
- They arrange visualizations into dashboards to monitor key performance indicators (KPIs) or answer specific business questions.
- Dashboards and reports are shared with stakeholders who can interact with them, filtering data or drilling down for more detail.
However, getting data reliably and securely into the BI tool presents its own set of challenges, particularly for engineering teams:
- Data Freshness & Reliability: The BI tool is only as good as the data it receives. If the ETL/ELT pipelines fail or run slowly, the dashboards will be out of date or incorrect. Ensuring robust, scheduled, and monitored pipelines is essential.
- Data Model Complexity: If the underlying data warehouse/lake schema is overly complex or poorly designed, creating visualizations can be difficult or lead to incorrect results. The data needs to be modeled in a way that is intuitive for analytical querying.
- Authorization and Access Control: Managing who can see what data within the BI tool is critical, especially when dealing with sensitive information. This often involves setting up roles and permissions that mirror business hierarchies or data sensitivity levels, requiring coordination between engineering, data teams, and IT.
- Connecting to Sources: While BI tools connect to many sources, getting performant, secure connections from the BI tool (especially if it's SaaS) to internal data sources (like databases behind a firewall) requires careful network configuration, VPNs, or ensuring data is first moved to a cloud-based data warehouse/lake.
Despite the technical challenges in feeding them, remember the most crucial aspect of BI tools: their value is entirely dependent on whether the insights they provide are useful for making decisions. A beautiful, real-time dashboard showing irrelevant data is useless. A simple chart from slightly older data that clearly answers a critical business question is invaluable.
Start by understanding the decisions that need to be made and the questions that need answering. Then identify the data required. Then figure out how to process it. Then select and configure the BI tool to visualize it. The tool is an enabler, not the objective.
Conclusion: Starting with the Question
Getting into analytics as an engineering organization can seem daunting, involving new tools, concepts, and data sources scattered across the company. However, by breaking it down into the three core components – understanding your data sources, processing that data, and using BI tools to gain insights – the path becomes clearer.
The most important takeaway from this introduction is to start with the question, not the data or the tools. Identify the business decisions you want to improve, the performance you want to track, or the user behavior you want to understand. This will dictate what data you need and how it needs to be processed and presented.
Prioritize understanding your data (Step 1) and defining the valuable insights (Step 3). Don't feel pressured to build a fully automated, enterprise-grade ETL/ELT system (Step 2) from day one. Validate your data sources and desired outcomes manually first. Automate strategically, focusing on pipelines that feed proven, valuable insights.
Analytics is an iterative process. You'll start simple, gain some insights, which will spark new questions, requiring new data or processing, leading to more insights, and so on.
In our next post, we'll take these foundational concepts and explore how to set up a basic analytics platform using readily available tools, focusing on getting that crucial initial business intelligence flowing. Stay tuned!