Productivity Metrics
Core Productivity Metrics for the Engineering Department

As the team grows, it becomes increasingly difficult to make sure that the entire department is being productive. Depending on anecdotal evidence from more layers of management opens itself to a biased review and potentially a popularity contest again. To hedge against that, having some key productivity metrics in place makes it easier to know that the team is operating at some minimum level so that you can tackle bigger problems.
This should also be paired with some domain specific metrics as well that can be utilized for more than one department. What that is depends on the organization and won't be discussed here but the framework and code is reusable to create an automated dashboard for it.
Lower Build Times
An example of a key productivity metric is build times. The lower the build times, the less chance there is of a productivity loss. When many engineers are working on the same code base, especially in product based start ups where there's one core application, waiting for pull requests to land onto the main branch can be a productivity killer. You've done all the testing, everything works locally, your PR (pull request) gets approved then CI kicks off and tries to merge yours and everyone else's approved code into main/master. However, something goes wrong whether there are new test cases that fail due to side effects, or the build has an issue etc. There could be lots of new tests or some very slow tests added. You could be waiting many minutes or hours for your code to land. Since your branch didn't land, your feature is not ready to be deployed into production at the next release. You can't close off that ticket and you end up context switching to try to be productive. We all know how context switching too much is also a productivity killer.
Regardless of the issue, as managers, we can keep an eye on the overall situation without going into very specific PRs by looking at build times. Build times is also a fickle thing, you can't solve it once and then let it go. It needs to be revisited often as the code base grows and legitimate tests get added.
What you can do is create a dashboard where the backing data is periodically synced to some data lake. Almost all the CI tools out there have API endpoints that you can code against very quickly. The example below:
- uses Looker Studio for creating dashboard.
- has a Python cron job that integrates with Github Actions and pushes the data to BigQuery. The data is granular enough to provide multiple insights using the dashboard. Be careful about pushing summarized data as you lose the flexibility of BI (Business Intelligence) tools to do its own aggregation and insights.
- the Python job uses a blob store as a state manager to be cost effective. It will query builds since the last sync date to be performant and non spammy
- uses some fake data for illustration purposes
Tip
Here's the code for the metrics. It'll evolve over time. PRs are welcome to add additional integrations. Metrics repository on Github The infrastructure code and permissions is out of scope for the project because it depends on where and how you deploy your cron jobs.
Here are the sample runs:
This is the Github workflow that we want to grab from the API:

This is a run from the CLI. At first, the GCS bucket doesn't have a state file so it looks back 30 days (configurable). The second run doesn't pick up the workflow as intended because the state file now exists and has been updated. No new workflow runs have been kicked off since.
Finally we push the raw data into BigQuery.

The final result is this dashboard which pulls from BigQuery:
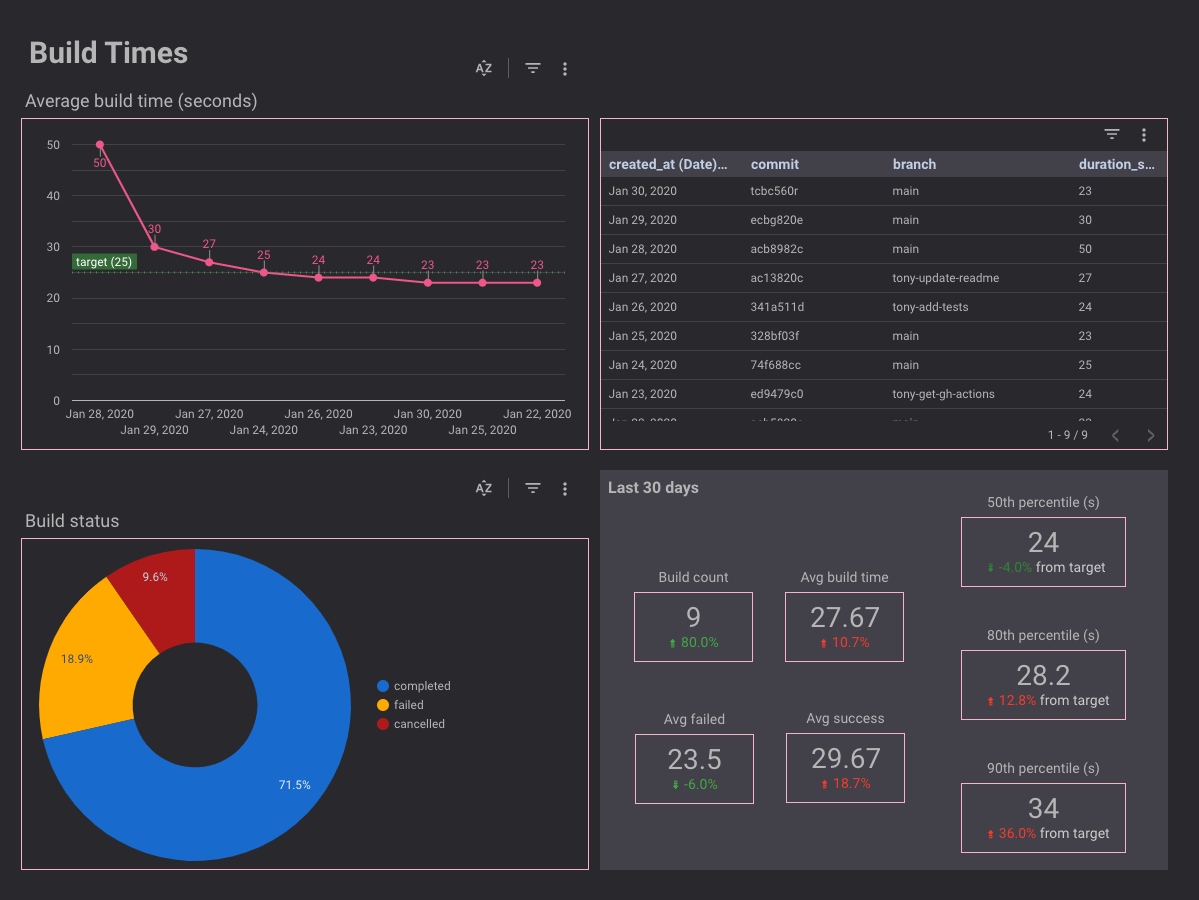
Let's break down the dashboard a bit further:
- At the top left, you can see over time how the build times are trending. You can set a target (in this case 25s) to see how it trends around that target.
- At the top right, you will be able to quickly identify offending commits if they blow out build times.
- At the bottom left, the main insight is ensuring that most builds are completing successfully.
- At the bottom right, you'll be able to see at different percentiles, what the build times are. You'll want at least the 90th percentile to be close to the target. But realistically you should settle for something lower like the 80th if your code base is tricky and non deterministic e.g. it runs solvers that can give varying results or it's integration test heavy. There should be a line somewhere with the 90th at the ideal mark and leaving some room for those experiments branches that could be slow.
At a glance, you'll be able to see the build time health. The breakdown allows you and the team to dig into issues if required.
Generalizing the Build Times for Other Like Metrics
You could apply the same dashboard to different data types for similar insights. Here are some ideas:
- Code review closing times - Engineers should be unblocking others and reviewing code quickly. The faster it gets reviewed, the faster it can be iterated upon and landed
- Issue resolution times - Issues of various priorities from a ticketing system can use a similar dashboard. The faster people triage, debug, resolve and deploy issues, the more productive the team is. Also consider putting a priority on the issues so you only focus on high priority ones that demand the team's immediate focus -- as opposed to a minor bug which gets prioritized like any other feature and suffers from those same issues (see below).
- Feature ticket closing times - Same idea as issues, but it be careful of this one as different teams operate differently and have different estimations. Teams may also slow down for different reasons like having holidays, people going on annual leave, doing R&D etc. It's not something I would normally track so use this one with caution. Issues are more important as they affect internal or external customers and there should be fewer of them.
- Security and CVE (Common Vulnerabilities and Exposures) SLA compliance - When dealing with ISO certifications or SOC2 Type II compliance, SLAs for vulnerabilities need to be met, otherwise they'll be marked down as exceptions in the compliance report. This dashboard can be used for keeping tabs on SLA resolution times.
Domain Specific Productivity Metrics That Unify the Org
Some context: At Neara, where I'm the Head of Engineering at the time of writing, we produce a 3D, engineering grade model of Utility networks. This is done through many data sources including LiDAR, satellite imagery, engineering specs, other GIS data etc. What ultimately comes out is a vectorized asset i.e. Poles and Cables. They're very rich and deep models. It may look like a simple 3D rendering on the screen but there's a bunch of physics, forces etc behind the scenes to run simulations. These poles and cables are the digital twin.
Utilities can have hundreds of thousands of kilometers of poles and cables in their network. So Neara uses AI to help speed that process up with very high accuracy. If anyone has worked with much AI, you know that getting the last 2% is extremely difficult. That's why we have people who go into problematic areas and use various CAD style editing tools to fix up the bad parts. This involves moving the pole position, adjusting the cable count, changing the assembly type etc. This is a lot of manual labour over that size of network.
So the north star metric that came out of this was: km/h.
The thought process behind this is that regardless of whether we used AI or human labour, we needed to digitize the utility network first before we can run weather simulations, do risk analysis etc. No insights are derived until the digital twin exists. So across departments, everyone works together to tandem to support the increase in km/h. That is, an increase in km/h is a productivity gain and slow down in km/h is a productivity loss.
The reason why this metric is so good is that it unifies all departments so that it's not gamifiable. The teams responsible for manual fix ups need to work with software teams that improve the tooling. AI teams can improve the tooling as well by adding in smarts and algorithms that auto suggest fixes. A large AI model can run more accurate classification of LiDAR which makes downstream algorithms more accurate in choosing the right pole. They're all interconnected and driving towards increasing this one metric.
Final Thoughts
This is just the introduction to metrics. There's much more to be said and shown. Aside from the time based metrics, ensure that some metrics are baked into CI. This includes things like code coverage, vulnerabilities etc. The next parts will discuss additional topics like developer quality of life surveys and how we can leverage AI -- large language models (LLMs) in particular to help provide further insights into productivity.